Four weeks ago I sat down with one goal. Pick the right AI memory tool for my second brain. I figured I would read three comparison posts, pick whichever one had the most GitHub stars, and ship something by the weekend.
Four weeks later I have a 40-tab browser session, half a Notion page of benchmark notes, and a quietly uncomfortable realisation: the tool most people recommend is not the one I picked, and the tool I did pick is one a lot of builders have never heard of.
This post is everything I learned about AI memory tools. The 7 systems that actually matter, how they really work under the hood, the benchmarks that are honest and the ones that are marketing, and what I ended up choosing for my personal AI second brain.
If you use Claude, ChatGPT, Cursor, or any AI tool daily and have ever felt like you are typing the same context into a new chat for the tenth time this week, this is for you.

What “AI memory” actually means (30 seconds for beginners)
Every AI chat you have today starts from zero. Claude forgets. ChatGPT forgets. Cursor forgets. Their built-in memory features are small, scoped to one app, and mostly a glorified sticky note.
An AI memory system is a separate layer that sits between you and every AI tool you use. You feed it your conversations, your notes, your links, your Slack messages, your GitHub activity. It stores them, understands them, and feeds the right slice back into any AI tool when you need it. Call it an AI memory layer, an AI memory framework, or a second brain. Same category.
Think of it like this.
Without a memory layer, every AI session is a Monday morning after a long vacation. Empty head. Rebuild context from scratch.
With a memory layer, every AI session starts with the AI already knowing what you were working on last week, what your clients have said, what patterns your own notes show. You stop explaining yourself.
This is not a Notion plugin. This is not a ChatGPT feature. This is an entirely different layer of software, and it has become its own category with its own leaders, its own benchmarks, and its own war.
Why I went looking for one
I handle marketing and growth across six WordPress products at POSIMYTH. I ship content, analyse SEO data, manage a team, run campaigns, talk to customers in Slack, track work in ClickUp, review code on GitHub. My life has about 10+ apps in it every day.
My brain is full. My AI tools are not, because they keep forgetting what I told them yesterday.
I wanted one thing. A persistent memory for AI agents that every tool I use can read from and write to. One mind. One base.
That is when I fell in.
But Claude already has memory. And claude-mem exists. Why do I need anything else?
Fair question. I hear it every time someone sees my setup.
Both of these are real, both work, and both are part of my stack. They just solve a tiny slice of the problem.
Claude Memory is Anthropic’s built-in feature inside claude.ai and Claude Desktop. It lets Claude remember your preferences and some context across chats. It is genuinely useful. It will remember that you prefer TypeScript, or that you run a marketing team, or that you always want bullet points instead of prose. Turn it on, it costs nothing.
claude-mem is a separate open-source plugin for Claude Code, built by thedotmack. It auto-saves your Claude Code sessions, compresses them, and reinjects the right slice of context when you open a new session. If you have ever had to re-explain a codebase to Claude every morning, this is the fix. Install in minutes: github.com/thedotmack/claude-mem.
I run both. So should you.
But neither is a second brain. Here is what they cannot do.
- They only live inside Claude. Claude Memory does not travel to Cursor, Windsurf, Codex, or any AI agent you build yourself. claude-mem is Claude Code only. Switch AI tools and you start from zero every time.
- They cannot ingest your stuff. Claude Memory does not read your Slack, your GitHub, your Gmail, your ClickUp, your voice notes, your browser history. It only remembers what you type directly to Claude. A second brain is supposed to remember everything you do, not only what you said to one app.
- They are small. Claude Memory has a hard cap you bump into faster than you expect. It is a sticky note on Claude’s fridge, not a pantry.
- You do not own the data. Claude Memory lives on Anthropic servers. You cannot export it, cannot query it with SQL, cannot run it offline, cannot take it with you if you ever leave Anthropic or if they change the feature.
- They cannot reason across time. Neither one tracks how your beliefs or your clients or your projects have changed. “What did I think about this client in March” is not a question they can answer.
So the right mental model is three layers, not one.
| Layer | What it does | Example tool |
|---|---|---|
| App memory | Claude remembers your preferences inside its own apps | Claude Memory (built in, free with Claude) |
| Session continuity | Each new Claude Code session does not start from zero | claude-mem (MIT, open source) |
| Your actual second brain | Persistent, cross-tool, queryable, owned by you, ingests from everywhere you work | MemPalace, Graphiti, mem0, and the rest of this post |
All three stack together cleanly. They do not compete. You should have all three. The one most people are missing is the third, and the rest of this post is about picking that one.
| Dimension | Claude Memory (built-in) | claude-mem (plugin) | mem0 / OpenMemory | MemPalace | Graphiti |
|---|---|---|---|---|---|
| What it is | Anthropic’s native memory inside Claude apps | Claude Code plugin that auto-saves sessions and reinjects context next time | Open-source memory layer with LLM fact extraction + vector search | Open-source verbatim memory, 96.6% on LongMemEval | Open-source bi-temporal knowledge graph |
| Where it runs | Anthropic’s cloud | Your machine (Claude Code only) | Your machine (Docker) or mem0 cloud | Your machine (pip install) | Your machine (Docker + graph DB) |
| Works with | claude.ai, Claude Desktop | Claude Code only | Claude Desktop, Code, Cursor, Windsurf (via MCP) | Claude Desktop, Code, Cursor (via MCP, 29 tools) | Claude Desktop, Code, Cursor (via MCP) |
| Memory scope | Per user, Claude apps only | Per Claude Code session | Cross-app via MCP | Cross-app personal knowledge base | Cross-app reasoning graph |
| Storage | Anthropic cloud (you do not see it) | Local markdown + SQLite | Postgres + vector DB | SQLite + Chroma (local) | Neo4j / FalkorDB / Kuzu |
| Self-host? | No | Yes (local plugin) | Yes (Docker) | Yes (pip) | Yes (Docker) |
| LLM cost on save | Included in your Claude plan | None (it is just saving sessions) | Per-save LLM call (adds up) | Zero (local embeddings only) | Per-episode LLM call |
| License | Proprietary (Anthropic) | MIT | Apache 2.0 | MIT | Apache-style |
| GitHub stars | n/a (not OSS) | Smaller (niche plugin) | 53k | 46.7k | 25k |
| Best for | Casual Claude users who want their chats to remember preferences | Claude Code power users who hate re-briefing every session | Apps, chatbots, SaaS that need memory across many users | Personal second brain that stores everything forever, evergrowing, low cost | Agents and products that need to track how facts change over time |
| Biggest limit | Locked to Claude, tiny scope, no API, cloud-only | Only works in Claude Code, not a full “brain” | Flat facts, 49% on temporal reasoning, LLM cost per save | Newer (2025), no native Slack / GitHub / ClickUp connectors | Needs LLM on every ingestion, graph DB ops required |
The bet behind all of this: the AI operating system for modern WordPress agencies
If you read this far, you probably see where I am placing my bets. AI is not just changing how we work. It is changing how the internet works. A second brain fixes how your AI remembers. The other half of the problem is the web itself.
At POSIMYTH Innovation Labs we are building SproutOS: WordPress for the new internet. A new way to build and manage sites without a dozen tools and plugins stacked on top of each other.
If you have a WordPress site, get on the list: sproutos.ai.
The 7 AI memory tools that actually matter (at a glance)
These are the ones that pass three filters: they exist, they are being used, and they actually remember things across sessions. Seven of them: mem0, MemPalace, Graphiti, Letta, Supermemory, Khoj and Cognee.
| Tool | GitHub Stars | Type | License | Self-host | Benchmark note |
|---|---|---|---|---|---|
| mem0 | 53k | Vector + LLM facts | Apache 2.0 | Yes | ~85% general, 49% temporal |
| MemPalace | 46.7k | Verbatim + temporal KG | MIT | Yes | 96.6% LongMemEval |
| Graphiti | 25k | Bi-temporal knowledge graph | Apache-style | Yes | ~85%, 15pt lead on temporal |
| Letta | 22.1k | Stateful agent + memory blocks | Apache 2.0 | Yes | Not benchmark-focused |
| Supermemory | 22k | Connector-first SaaS | MIT repo / closed engine | Enterprise-only | 81.6% (self-reported higher) |
| Khoj | ~20k | Self-hosted second brain app | AGPL-3.0 | Yes | n/a |
| Cognee | 15.5k | ECL pipeline + graph + vector | Apache 2.0 | Yes | Not published |
Stars are a popularity signal, not a quality signal. mem0 has the most. MemPalace is a surprise in second place for a system most people have never heard of. We will get to why.
The one thing most comparison posts get wrong: a brain is not a notebook
Before comparing tools, we have to talk about the difference that makes this whole category interesting. It is the thing most reviews miss, and it is the single biggest reason one tool is right for you and another is not.
A notebook stores facts. A brain holds beliefs that change.
Let me show you what that means with a real example.
The Ravi scenario
Say I am talking to a lead named Ravi. Here is how the month plays out in real life.
April 2. I capture the thought: “Ravi from Studio X is evaluating The Plus Addons for Elementor for a multi-site license.”
April 14. I capture: “Ravi went with SproutUI instead, pricing was the blocker.”
April 20. I ask my AI: “What is happening with Ravi?”
Here is what happens in each tool.
In mem0 (the notebook pattern): Both facts are stored. Both have timestamps. When I query, both come back. My AI has to read both and guess which one is current. Often it gets confused and says something like “Ravi is evaluating The Plus Addons for Elementor but also uses SproutUI,” which is not right. The old belief never dies. This is why mem0 scores ~85% on general recall but drops to 49% on the temporal subset of LongMemEval (Atlan 2026 benchmark). When the question is “what did I believe when, and what changed”, mem0 fumbles.
In Graphiti (the brain pattern): When the April 14 capture comes in, Graphiti looks at the existing edge Ravi --evaluating--> The Plus Addons for Elementor, sees that the new belief contradicts it, and invalidates the old edge with a valid_to = April 14 timestamp. It creates a new edge Ravi --purchased--> SproutUI with valid_from = April 14.
When I query on April 20, only the currently-valid edge comes back. When I query “what were we tracking with Ravi on April 10,” I get the old edge, because it was valid then. This is called bi-temporal reasoning.
Graphiti scores 63.8% vs mem0’s 49% on the same temporal subset (Zep paper). 15 points. That is not a rounding error. That is the difference between guessing and knowing.
In MemPalace (the verbatim pattern): A third path. Store everything raw, no LLM extraction at ingestion, no graph building that could drift when models change. When I query, it retrieves the best semantic matches and a small deterministic temporal graph layer ranks them. The reasoning happens at query time, not at write time. It scores 96.6% on full LongMemEval (MemPalace 2026 ranking). The highest I found.
Why this matters for you
If your AI memory is a flat notebook, every contradictory fact adds confusion. If it is a brain, contradictions update beliefs. If it is verbatim storage done right, contradictions stay separate and the retrieval layer handles time.
This is the axis that actually matters when you pick an AI memory framework. Star count is marketing. Temporal reasoning is product.
The 7 AI memory tools, one by one

1. mem0: the ecosystem winner (@mem0ai)
- Stars: 53k (github.com/mem0ai/mem0)
- Funding: $24M Series A from YC, Peak XV, Basis Set (TechCrunch, Oct 2025)
- Built for: dropping persistent memory into any chatbot or AI agent, fast.
- What it is: A vector store with an LLM extraction layer on top. You send in conversations, the LLM pulls out “facts,” they get stored with embeddings, you search by similarity.
- If you are a SaaS founder, you can build: a customer support bot that remembers every past ticket a user raised. An AI tutor that remembers what a student has mastered. A fitness app AI that remembers what you ate last week. A dating app AI companion that gets less generic the longer you use it. Anything with “AI chat” in the roadmap.
- If you are using it yourself: make your side-project chatbot stop forgetting who you are. Great for anyone prototyping with LangChain or LangGraph.
- Strengths: Biggest community, most integrations, AWS Agent SDK default, works out of the box, self-hostable via Docker.
- Weaknesses: No temporal reasoning. Facts are flat. Contradictions stack, they do not resolve. 49% on the temporal subset of LongMemEval is the ceiling.
- Verdict: the safest B2C chatbot memory. Not the right pick for a true “second brain.”
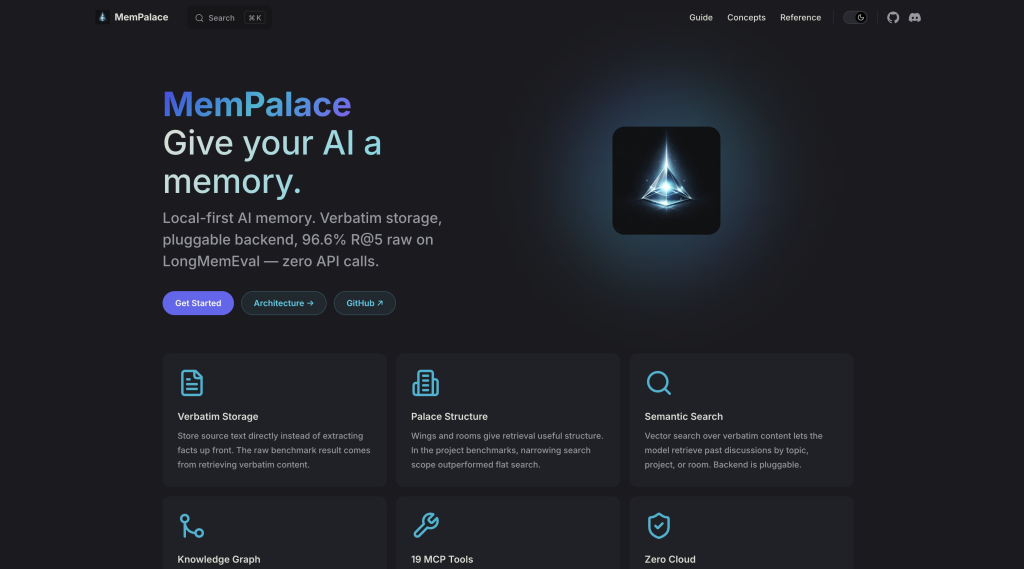
2. MemPalace: the quiet benchmark leader (@MemPalace)
- Stars: 46.7k (github.com/mempalace/mempalace)
- Backstory: Built by actress Milla Jovovich and dev Ben Sigman using Claude Code itself. Yes, really.
- Built for: a personal second brain that stores everything forever, does not bleed LLM cost on every save, and can be queried from any AI client over MCP.
- What it is: Your content stored verbatim in a palace-metaphor structure (wings, halls, rooms, drawers), with a small local temporal-entity graph and ChromaDB for semantic search. Critical fact: the default mode uses zero LLM calls on ingestion. Local embeddings only. 300 MB model, runs on CPU.
- If you are a SaaS founder, you can build: a “private AI vault” for knowledge workers, writers, or researchers. A journalist’s research memory tool that does not leak to OpenAI. A writer’s notes + query app that scales without LLM bills killing margin. A founder’s idea journal SaaS where the user owns everything. A lawyer’s case-prep assistant where costs per save cannot balloon.
- If you are using it yourself: dump every link, voice note, article, client update into one place. Query in natural language. Costs pennies per month instead of dollars per day.
- Strengths: Highest benchmark score in the field. No LLM cost at ingestion. MIT license. 29 MCP tools built in so Claude Desktop and Cursor plug in directly.
- Weaknesses: Newer (late 2025). No native Slack / GitHub / ClickUp connectors (same gap as every OSS option). Less production track record.
- Verdict: the cost-aware benchmark leader. Best pick if you want a self-hosted AI memory that stores a lot without hemorrhaging tokens.
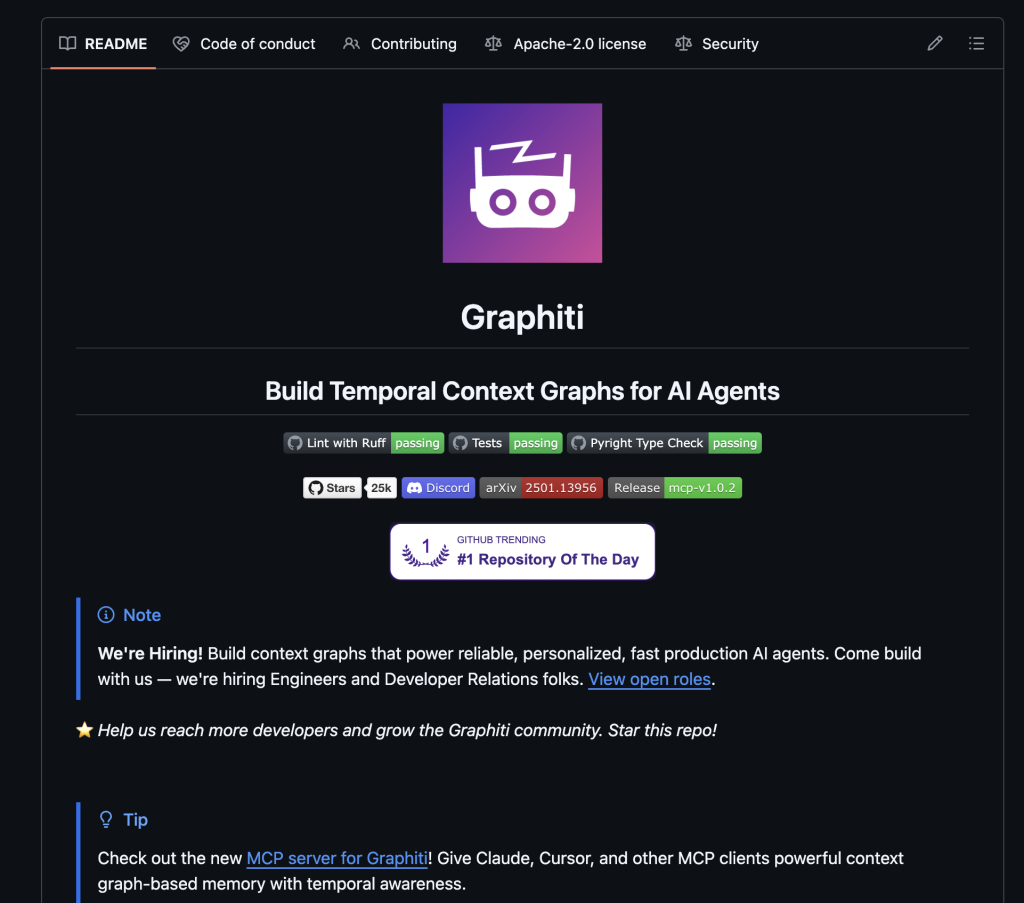
3. Graphiti: the brain that actually thinks in time (@zep_ai)
- Stars: 25k (github.com/getzep/graphiti)
- Built for: agents that reason about how facts change over time, not just what is true right now.
- What it is: The open-source bi-temporal knowledge graph engine powering Zep Cloud. Tracks four timestamps per edge: created_at, valid_at, invalid_at, expired_at. Facts get invalidated, not deleted.
- If you are a SaaS founder, you can build: a CRM where the AI actually knows the current state of a deal instead of surfacing contradictory old notes. A legal research product that shows how a case’s argument evolved. A compliance tool where “what was true in Q2 2025” is a real answerable query. A sales intelligence platform that tracks how a prospect’s stance shifted over six months. A portfolio management AI that remembers every thesis change and why.
- If you are using it yourself: track your own decisions across projects. See how your thinking on a client, product, or strategy has shifted over months. Perfect for consultants, researchers, operators.
- Strengths: The reference implementation for temporal reasoning. Zep’s paper showed +18.5% over MemGPT on LongMemEval and compressed context from 115k to 1.6k tokens. First-class MCP server in the repo. Backends: Neo4j, FalkorDB, Kuzu embedded, Amazon Neptune.
- Weaknesses: No native connectors. LLM called on every episode to extract entities (cost adds up). Needs a graph DB and a bit of ops.
- Verdict: the serious pick for anything where time + change matters. The best AI knowledge graph option in this list.
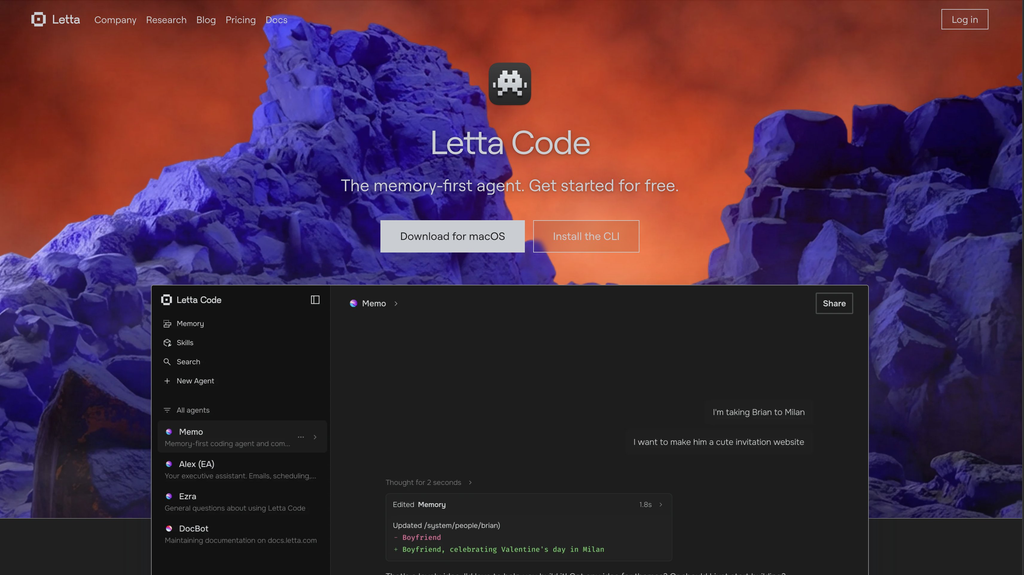
4. Letta: the agent, not the memory (@Letta_AI)
- Stars: 22.1k (github.com/letta-ai/letta)
- Funding: $10M seed at $70M post from Felicis.
- Backstory: This is the MemGPT team, rebranded. MemGPT the product is defunct, MemGPT the paper is the ancestor.
- Built for: autonomous agents that learn and edit their own behaviour over time.
- What it is: A stateful agent runtime with self-editing memory blocks. The LLM reads and edits labeled memory blocks as tool calls. Core context (in-prompt) + recall (vector) + archival (storage), all OS-metaphor.
- If you are a SaaS founder, you can build: an “AI employee” product that learns a job role over weeks. A coding agent that learns your team’s style without constant re-prompting. A recruiter assistant that learns each client company’s hiring pattern. A customer success AI that remembers the personality of each account. A sales SDR agent that evolves its pitch based on what closed last month.
- If you are using it yourself: a daily assistant that adjusts its persona as it learns your preferences, so you stop re-briefing it every morning.
- Strengths: Best MCP client in the field. Your agent can read from any MCP server you already run. Self-editing persona. Sleep-time agents for background processing.
- Weaknesses: Not a memory system, it is an agent framework that uses memory. LLM-heavy by design. Higher per-operation cost. Letta Code pivot (March 2026) is removing some server-side features.
- Verdict: the agent layer, not the memory layer. Pair it with something else as the store.
5. Supermemory: the polished one with a catch (@supermemory)
- Stars: 22k (github.com/supermemoryai/supermemory)
- Backstory: 20-year-old solo founder Dhravya Shah, $2.6M seed backed by Cloudflare execs, Jeff Dean, Logan Kilpatrick, David Cramer (TechCrunch).
- Built for: SaaS products that want memory + OAuth connectors (Drive, Gmail, Notion) without building them.
- What it is: API-first memory layer with connectors and a clean MCP server. Relational versioning with three edge types (updates, extends, derives) and dual timestamps (documentDate + eventDate).
- If you are a SaaS founder, you can build: a team knowledge product where users plug in Google Workspace and the AI just works. A “your company, queryable” tool for SMBs. A sales enablement platform that reads from Drive and Notion and answers questions for the whole team. Any AI product where the fastest path to value is “connect your stack, get results.” You save weeks of OAuth + webhook + rate-limit work.
- If you are using it yourself: connect Drive + Gmail + Notion in ten minutes, query across all three from Claude Desktop.
- Strengths: The only system here with native first-party connectors at the memory layer. Great DX. Sub-300ms retrieval. SOC 2, HIPAA, GDPR.
- Weaknesses: Self-hosting is enterprise-only. The MIT repo is a shell, the real engine is closed and deployed on Cloudflare Workers. No Slack, no ClickUp, no Linear/Jira native. Gmail connector is gated behind the $399/mo Scale plan. Independent benchmarks show 81.6% on LongMemEval, under their marketing claim.
- Verdict: best-in-class if you can pay and you need the connector polish. Wrong pick if you want to self-host as a solo operator.

6. Khoj: the closest thing to a second-brain app in a box
- Stars: ~20k (github.com/khoj-ai/khoj)
- Built for: individual users who want a self-hosted AI chat over their own files and notes, out of the box.
- What it is: A fully self-hosted AI second brain with chat interfaces for Obsidian, Emacs, WhatsApp, desktop, browser, and phone. Notion connector, local Ollama support, built-in RAG pipeline.
- If you are a SaaS founder: less relevant as a backbone since AGPL-3.0 is viral for embedding, but a great reference product to study if you are designing a consumer second-brain app.
- If you are using it yourself: point it at your Obsidian vault or a folder of notes, get a private AI chat that never leaves your machine. Privacy-focused professionals (lawyers, therapists, medics, anyone handling sensitive data) love this.
- Strengths: Closest spiritual prior art for a ready-to-deploy second brain. Active community. Local-first privacy story.
- Weaknesses: GitHub connector is deprecated. Underlying memory layer is simpler than Graphiti or MemPalace. AGPL-3.0 matters if you ever want to commercialise.
- Verdict: the best “download and use” option. Less good if you want a primitive to build on.
7. Cognee: the pipeline approach (@cognee_)
- Stars: 15.5k (github.com/topoteretes/cognee)
- Built for: developers who want a pluggable ingestion pipeline into a graph + vector store with real reasoning in it.
- What it is: An Extract-Cognify-Load pipeline. You feed it data, it runs six stages (classify, permission, chunk, extract entities, summarise, embed + commit), and it stores into a graph + vector store. Default stack is SQLite + LanceDB + Kuzu, all embedded, zero external services.
- If you are a SaaS founder, you can build: a domain-specific AI (legal research, medical Q&A, finance analyst) where your ingestion rules are the moat. A vertical AI product for an industry where generic RAG fails. A “company brain” product where custom entity extraction per document type is the actual value. A research AI for a specific discipline where your classifiers and pipelines are the IP.
- If you are using it yourself: write your own loaders for obscure sources, get a clean graph + vector store, query from anywhere. Good if you enjoy controlling every pipeline stage.
- Strengths: Easiest zero-dep self-host. Real reasoning in the pipeline (memify() reweights edges by usage, derives new facts). Widest connector breadth in the OSS space via cognee-community.
- Weaknesses: LLM cost per ingestion. No published LongMemEval score. Smaller community than mem0.
- Verdict: pick this if “custom pipeline” is the actual product, not just plumbing.
Best AI memory tool by use case: pick by what you actually need
| If you need | Pick |
|---|---|
| The biggest ecosystem + plug-and-play | mem0 |
| Highest recall benchmark + no LLM on save | MemPalace |
| True temporal reasoning, “what changed when” | Graphiti |
| An agent that edits its own behavior | Letta |
| Native Slack + Gmail + Notion connectors out of the box | Supermemory (if you can self-host via enterprise) |
| A ready-to-use second brain app | Khoj |
| A full ingestion pipeline you control end-to-end | Cognee |
The value bomb: what you can build with each AI memory tool
If you are a builder, every tool on this list is a different product unlock. Same category, totally different shape of what you can ship. Here is the map.
| Tool | SaaS product you can ship | Daily-life product you can ship |
|---|---|---|
| mem0 | AI customer support that remembers every past ticket. AI tutor that remembers what a student has mastered. Fitness AI that remembers your week. Companion apps. | Side-project chatbot that stops forgetting you. Personal Slack AI for one user. |
| MemPalace | Private AI vault for knowledge workers. Journalist’s research memory tool. Writer’s notes + query app with healthy margins. Lawyer’s case-prep assistant. | A lifetime second brain where every note, voice clip, link you drop in stays forever and costs pennies to query. |
| Graphiti | CRM that actually tracks how a deal evolved. Legal research tool that shows argument drift. Compliance SaaS where “what was true in Q2” is a real query. Portfolio AI that remembers every thesis change. | Decision journal that remembers when you changed your mind and why. |
| Letta | “AI employee” SaaS that learns a role. Coding agent that learns your team’s style. Recruiter AI that learns each client’s hiring pattern. Customer success AI that remembers account personalities. | A daily assistant that evolves its persona with use instead of resetting each morning. |
| Supermemory | Team knowledge SaaS where users plug in Google Workspace and the AI just works. “Your company, queryable” for SMBs. Enablement products that read from Drive and Notion. | Personal cross-app query tool if you can pay for the Scale plan. |
| Khoj | Less relevant as a backbone (AGPL is viral). Great reference product to study for consumer second-brain UX. | Private AI over your Obsidian vault. Privacy-first AI for lawyers, therapists, anyone with sensitive files. |
| Cognee | Vertical AI for legal / medical / finance where your pipeline rules are the IP. Company brain products where custom entity extraction per document is the moat. | Your own pipeline from any weird source into a graph + vector store, queryable from anywhere. |
The point: these are not seven versions of the same thing. mem0 is an engine for chatbots. MemPalace is a vault. Graphiti is a temporal reasoner. Letta is an agent runtime. Supermemory is a connector layer. Khoj is a consumer app. Cognee is a pipeline. They solve different problems, and if you pick the wrong one for your shape, the stars will not save you.
LongMemEval benchmarks cheat sheet
Published or independent scores on LongMemEval and related temporal memory benchmarks. Numbers below are from independent third-party sources, not from the vendors’ own landing pages.
| Tool | LongMemEval (general) | LongMemEval (temporal) | Source |
|---|---|---|---|
| MemPalace | 96.6% | : | mempalace.tech ranking |
| Hindsight | 91.4% | : | Vectorize / VentureBeat |
| Zep / Graphiti | ~85% | 63.8% | Zep paper, arXiv 2501.13956 |
| mem0 | ~85% | 49% | Atlan 2026 |
| Supermemory | 81.6% | : | Independent reading of mempalace ranking |
Read the LongMemEval paper if you want to understand what is being tested. Short version: it is the closest thing to an honest “does your memory actually work across long sessions” test this category has.
Two notes on honesty. One, Supermemory claims #1 on multiple benchmarks on its site. Cross-referenced with the MemPalace comparison, independent scores come in at 81.6%. Self-reported benchmarks should always be cross-checked. Two, Cognee has not published its LongMemEval score. That is a data point.
The graveyard: AI memory startups that died in the last 12 months
This is the part most posts skip. It matters, because the companies you were about to build your mind on are not all still standing.
- Rewind.ai / Limitless: Acquired by Meta, December 2025. Rewind Mac app killed December 19, 2025. Pendant sales stopped. Never shipped the public API they promised for years (9to5mac coverage).
- Heyday.xyz: Acquired by BetterUp, September 2024. Shut down.
- Humane AI Pin: Bricked every Pin on February 28, 2025. Sold to HP.
- Cove AI: Shut down April 1, 2026. Team joined Microsoft.
- Rabbit R1: 95% device abandonment rate reported. Struggling to make payroll.
- Pi (Inflection AI): Effectively abandoned. Founders went to Microsoft.
- Mem.ai: Called “the $40M second brain failure” in Medium coverage. Still operating but no momentum.
Lesson: this category eats hardware and eats consumer apps. The survivors are mostly developer infrastructure that can be self-hosted or has a clear API moat.
Another lesson: do not build your mind on a startup that can get acquired and shut down. If the code is open source and you hold the data, you are safe from this.
Other AI memory frameworks and mem0 alternatives worth knowing about
I focused on the 7 above because they matter most right now. But the category is big. Here is what else is out there, grouped so you can skim.
Agent memory research and experiments
- MemGPT paper: the original paper behind Letta. Worth reading.
- MemMachine: ground-truth preservation, tops LoCoMo benchmark, v0.2 community-driven after MemVerge.
- MemOS (MemTensor): MemCube abstraction for parametric + activation + plaintext memory, v2.0 Stardust.
- MemReader: the extraction model inside MemOS, not standalone.
- Hindsight (Vectorize): four parallel memory networks, 91% LongMemEval.
- Memvid: stores text as MP4 video frames, clever engineering.
- SuperLocalMemory: math-grounded local memory, zero-LLM mode.
- Mnemosyne: Tsinghua research paper, not productised yet.
Framework-native memory
- LangMem: LangChain’s memory SDK.
- LlamaIndex Memory modules: integrates with LlamaHub’s 300+ data loaders.
- Weaviate Engram: agent memory product on top of Weaviate.
- Pinecone Assistant: RAG over docs, cloud only.
- Microsoft Agent Framework: pluggable backend, replaces AutoGen.
Commercial memory APIs
- Papr Memory: predictive memory graph, native Slack / GitHub / Jira connectors, AGPL-3.0 OSS option.
- Memobase: user-profile memory for chatbots.
- Graphlit: 30+ native connectors (Slack, GitHub, Gmail, Notion, Jira, Linear), closed SaaS.
Consumer second-brain apps
- Tana: structured Supertags + AI agents.
- Heptabase: visual whiteboard with AI.
- Reflect: notes with MCP server.
- Capacities: WhatsApp + Telegram + Gmail capture.
- Saner.ai: ADHD-focused operator assistant.
- Reor: local desktop AI notes.
- Notion AI: Notion 3.2 agents, persistent memory inside Notion only.
Messaging-first AI assistants
- Notis: WhatsApp + Telegram + Slack + iMessage native, 800+ integrations.
- Zapia: WhatsApp consumer assistant, 5.5M LATAM users.
- Memorae: WhatsApp + Telegram second brain for reminders.
- Poke: messaging-native YC-backed, $300M valuation.
- Khoj WhatsApp: also fits here.
Claude-specific memory
- claude-mem: Claude Code session continuity plugin.
- OpenMemory (mem0 variant): local MCP for cross-IDE shared context.
Any of these might fit your stack better than the 7 I focused on. I went deep on the 7 because they appeared in every serious comparison I found, and because they span the real axes of this category: vector, graph, verbatim, agent, cloud, self-host, connector-led.
What I picked (and why I am not naming it yet)
After four weeks I picked one tool.
It is not the one with the most ecosystem. It is not the one VCs are funding hardest. It is not the one Zep’s cloud is built on.
It is the one with three things none of the others have together:
- It stores what I give it, verbatim, forever. No LLM extraction layer that drifts as models change next year. If I come back in 2030, my data is still my data.
- It does not call an LLM every time I save something. My Claude bill does not bleed on ingestion. The LLM only gets called when I am actually asking a hard question. That changes the math on “evergrowing mind.”
- It scored highest on the benchmark that measures the thing I actually care about. Higher than the 53k-star favourite. Higher than the $24M rising star. Higher than the engine Zep’s cloud runs on. The numbers are in the table above.
And there is a fourth thing I did not expect to matter: it was partly built using Claude Code itself, by two people, one of whom you have seen in movies. Something about a tool being built with the AI I use daily, by people outside the usual AI startup bubble, felt right. Good taste tends to show.
The full build, the exact setup, the pipeline, how it talks to my AI tools, and what it actually costs per month, is going into the next post.
If you want that, follow along.
Follow the build
I am documenting this whole thing in public on X. Not another AI newsletter. Not another prompt thread. The actual wiring. The actual cost. The actual failures.
My aim for the next 12 months is simple. Be in the top 1% of people using AI well. Not another generic ChatGPT user. Not another “AI is changing everything” poster. Top 1%, measured by what I ship.
Follow me on X so you do not miss it: @adityaarsharma.
Credits: benchmarks sourced from LongMemEval, Zep paper arXiv 2501.13956, MemGPT paper arXiv 2310.08560, MemPalace 2026 ranking, Atlan 2026 framework roundup, and Vectorize Hindsight coverage.